GraphQL, as most new programming techniques (or styles or libraries), is trying for the last couple of years to find its place into the world of software development. The problem arises when people try to evaluate new techniques without taking into account the past of the relevant technological sector. Even when a new technique really shines (and not just because it is new) is usually because it “stands on the shoulders of giants”. Though GraphQL is a very promising and interesting design style for APIs, it is not that far, conceptually, to REST or RPC APIs. as you may think. In order to understand this you have to focus in similarities more than to differences. You have to figure out how the same ideas or concepts of the past are now being re-used, just in a different way.
Here is the short story:
GraphQL starts as REST by defining resources. It, then, allows you to combine multiple resources that may required for an action, like the RPC does, by defining relations between the resources. It also achieves a high-level of discoverability by self-documenting itself through the __schema query, similar to what REST aspires to do through HATEOAS. Finally, it allows you to trim down the returned payload (lean responses) to your needs, as RPC is supposed to do, by allowing you to define the fields you want to retrieve.
Old ideas re-applied: Let’s take a closer look in thισ re-use of some old ideas.
GraphQL implements a concept of endpoints through its queries and mutations. Based on the data you want to retrieve or the job you want to do, you “call” the relevant query or mutation. Of course, all your HTTP requests are tunneled through the same URL and they are using the same HTTP verb, because now the selection of the “endpoint” takes place inside the request’s payload. This is where you mention which query or mutation you want to “call”.
You are still defining resources, somewhat like in REST APIs. Here your resources are defined as GraphQL types. Each type defines a data structure (the fields that are available for retrieval alongside their type) and the means to build this structure (give values to the fields based on the provided input). GraphQL types are built based on the information that you want to make available to the clients and the structure that is most useful for this purpose. For that reason, words “type” and “resource” (and, sometimes, “data structure”) will be used almost interchangeably throughout this article.
Relations between resources can be forged through fields. A type A can be related to another type B by adding to type A a field with a resolver that return a data structure of type B For example, a User type may have a “profile” field that is resolved (when asked for) as a data structure of Profile type with information about the user’s profile.
Although the GraphQL types are the resources that a client wants to retrieve, they cannot do it directly. They have to do it only through queries. Queries transform some of the resources to entry points for clients. That way, you API starts to look like a graph:
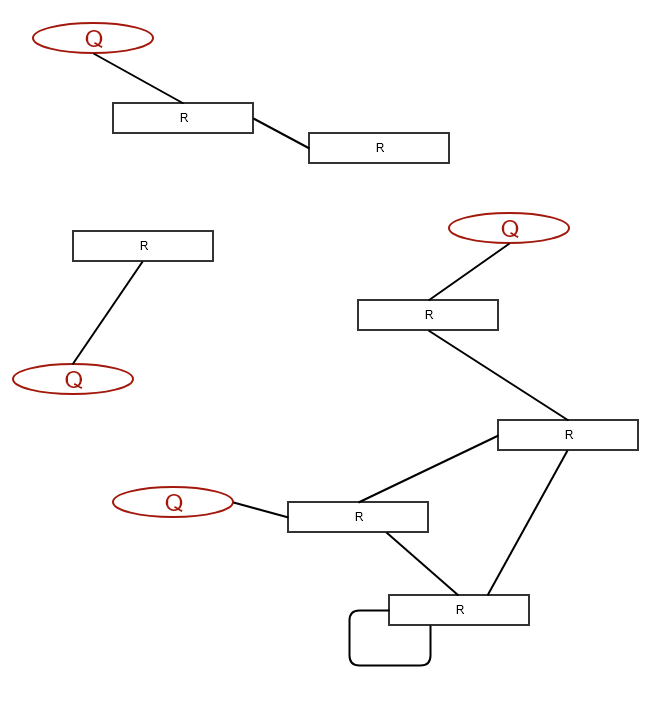
The main components: I haven’t mentioned mutations here for the sake of simplicity. There will be a comment about them a bit later in this article. After all, the main advantage of GraphQL is the retrieval of information. Now, let’s have a look at these two main components,the Types/Resources and Queries, that comprise the GraphQL schema.
First, the resource. A resource defines a data structure (an object structure, to be exact) as well as the way this structure is formed (gets its values). So, in order to define a resource we need 3 main pieces: (a) a name for the resource, (b) the input that we need in order to build the data structure and (c) the fields that comprise the data structure.

A field that has a “resource” type (and not a scalar one) defines a relation between resource types with utter purpose to allow the retrieval of nested related resources.

The most_recent_posts field has a POST resource type and this allows us to nest inside the user data structure the information about the user’s most recent post.
The resolvers are functions of the form: resolver(obj, args, ctx) and they may have 3 kinds of input:

The second component is the query.

Some misconceptions about GraphQL:
– GraphQL is not here to fix or improve REST, as REST was not here to fix or improve RPC! Please, don’t fall into the trap thinking that every new technology is better than any previous one. GraphQL is just a different approach to implement an API that works better is specific cases. So, as all approaches, it has its advantages and its disadvantages. In simple words, GraphQL is better choice for some cases as REST is better in some other cases ,etc.
– Yes, your resources may form loops! Circular references are not bad, neither good. It’s just a reality. That’s why is called a “graph”. Type A may have a field of type B, type B may have a field of type C and type C may have a field of type A. Nothing to worry about.
– A GraphQL resource (type) may or may not map to a database table. GraphQL resources express data structures that you want to provide to your clients. So, be open-minded. You may have a resource called “statistics” and calculate the statistics on demand. You don’t need to have a “statistics” table
– Yes, you can send more than one queries or mutations at the same HTTP request. And that’s because the real “entry point” for the GraphQL schema is not the specific query or mutation but the keyword that defines the type of the request. This keyword can be omitted when the request is for query(ies). These are equivalent:

You can also send the same query more than once (in case you want to use different input parameters to each query instance), by using aliases. Since your request can have only one type (query, mutation, subscription,…), you cannot combine queries and mutations in the same HTTP request.
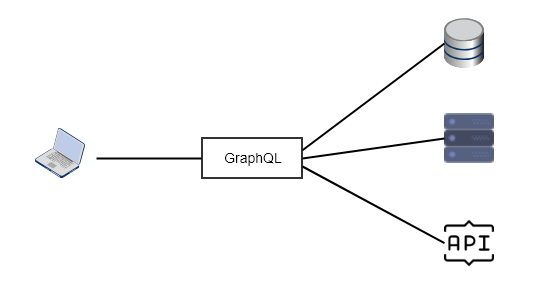
– The use of GraphQL does not imply that we don’t already have an API. GraphQL can gather the required information by talking to any kind of service: a database, another API, a filesystem,…whatever. In fact, GraphQL can act as middleware retrieving data by making calls to other services (web apps, databases, etc.). What is more, you are not limited in using only oine API design style. For example, you can use GraphQL for a part of your API and REST for another.
The pros and cons of the new approach:
The core ideas promoted by GraphQL are:
– resource nesting: allows the API to be flexible with the returned information without defining extra endpoints or expecting the client to do multiple HTTP requests to get what needed. Nesting is possible because of the graph formed between Resources/Types through relations. This leads to lean responses and low network overhead.
– automatic documentation: the advertised GraphQL schema is being automatically updated when a change happens. Automatic self-documentation is achieved through the __schema query (or “introspective query”) which returns the server schema. This leads to a high level of discoverability.
The main downsides of this new design style are:
– increased implementation complexity (compared to REST or RPC)
– caching (the root of the problem lies on the fact that GraphQL uses a single endpoint for all queries and mutations)
So, GraphQL can give you an advantage over other design styles when:
– you have multiple clients and each one needs to retrieve different kind (or sets of) data from the back-end
– the client (or UI) is changing frequently and so the data it needs to retrieve. This requires a lot of effort for back-end changes. If the one who is building the API does not belong to the same company that builds/maintains the backend/API, then a lot of communication should take place between these two.
Yes, this was Facebook’s case. Many mobile apps (clients), built by third-parties, that were using Facebook services. Each one with different requirements and needs. Clients mainly focused on reading data (queries) than writing data (mutations).
What is wrong with mutations:
It is just that GraphQL cannot offer much through mutations comparing to other design styles. It is difficult to harvest most of the GraphQL benefits through mutations. For example, if you send multiple mutations through the same HTTP request it is probably because all these action that you want to execute are part of the same business transaction. So, what happens if one of these mutations fail ? How can we know which ones failed ? And how can we reliably rollback to the previous state ? Offline locking won’t help. The situation is more complicated because these mutations do not form a chain a sequentially executed actions where each action is using the results of the previous one. The problem is more similar to the one of transactions in a system based on microservices. Another approach could be to use nested mutations but this requires a great increase in complexity and, again, keeping the system’s consistency in case of a failure is still questionable.