
Focusing on the wrong chapter
Let’s start with a groundbreaking(?) discovery. Concepts like “Entities”, “Value Objects”, “Repositories”, “Services”, referred as tactical patterns in DDD, are not discovered or originally proposed by DDD. They exist in the world of OOP before DDD[1]. The significant contribution of DDD is that it is enabling us to first think our problems as domain problems (business problems) and then as technical problems. The same goes for the design.
Tactical patterns are there to set an example. You don’t have to use them (at least, not as they are used in Eric Evans’ book) just because you are following the mentality of DDD. Some or all of them may not fit you problem or architectural design. Or you may use the patterns but you may name them anyway you like (or you see more appropriate based on their role in your architectural design).[1] For example, instead of a “repository” you may use the term “persistor”. Instead of “entity” you may use the term “domain object”. It is totally fine.
About a decade ago Eric Evans said that tactical patterns are overemphasized by people at the expense of the most important ideas in DDD. [10] Unfortunately, in 2021, Derek Comartin talks again about the excessive emphasis that has been given to DDD’s tactical design. [2] No only making many people thing that concepts like “entity”, “value object” “repositories” etc. are part of DDD but also that the core of DDD has to do with such low-level design details. The core of DDD is focusing on the problem domain, its modeling and the discovery of bounded contexts within it as well as the importance of those things. This is not one task, it can happen in many levels (from macroscopic to microscopic) and has several methodologies related to it (Event Storming is one of them but you don’t need to use it in order to be able to claim that you are following a DDD mentality).
The heart of DDD – Part 1: Understanding the (business) domain
Modeling is a tangible projection of a concept, suitable for the task it is going to be used at. So, there may be several ways to model a business concept or entity (a document, a process, an operation, a role) but not all of them will make our life easier when they are going to be used for a specific task. The task that our software is designed to implement. Each model may need different kind of information or information expressed in a different way. [5] So, there are a few question we should ask ourselves when modeling business concepts. What am I going to do with that model ? If I don’t know that, how can I know if the model I designed is useful ? Observe conversations that happen at business level or how different business experts (or non-experts, people from various departments) talk to you about the same issue. Detect different wording or terminology used for the same concept/process/task because, quite often, different wording indicates different viewpoints/approaches for the same thing. This variety of viewpoints can help you build candidate models for your design. Having alternatives helps you evaluate the pros and cons of each one and make better decisions. [5][8] It is something you should strive for.

DDD is also urging us to strive for a ubiquitous language in our software design. A common language between programmers and domain experts. e.g “crediting” a bank account instead of “increasing” it, “opening” a bank account instead of “creating” it.
And this ubiquitous language should go all the way down to the code. The use of such language, instead of creating our own technical language for the same concepts, lowers the toll software engineers have to pay in their communication with business people (actually, any person working in that business domain and who is not a software programmer).
Taking the domain into consideration when modeling our software is not a new idea. We have been doing that for a long time but to a much more limited extend. DDD extended the idea and provided methodologies.
The heart of DDD – Part 2: Bounded contexts
Definition and discovery: From a business perspective, a bounded context is a part/sector (e.g sales, logistics, warehouse, accounting, commercial,…) of the business domain that is self-contained to a high degree. In other words, a sector with an internal organization and functionality that is little affected by the internal organization of other business sectors. It also means that concepts are well and uniquely defined within the boundaries of this sector. These concepts, which may also be used in other business sectors, may have a different context/meaning in this sector (less, more or slightly different information may be kept in documents for this concept by this business sector than in other sectors) [1][2][3]. For example, the sales department of a online bookstore is interested in certain information about a book. Information about the sales of this book or information that is needed to promote the sales of the book (category, title, author, contents, reviews). The shipping department of the same bookstore cares about other kind of information related to a book that is being shipped (size, weight). In terms of information, the “book” concept means slightly different things for each of those two business sectors.
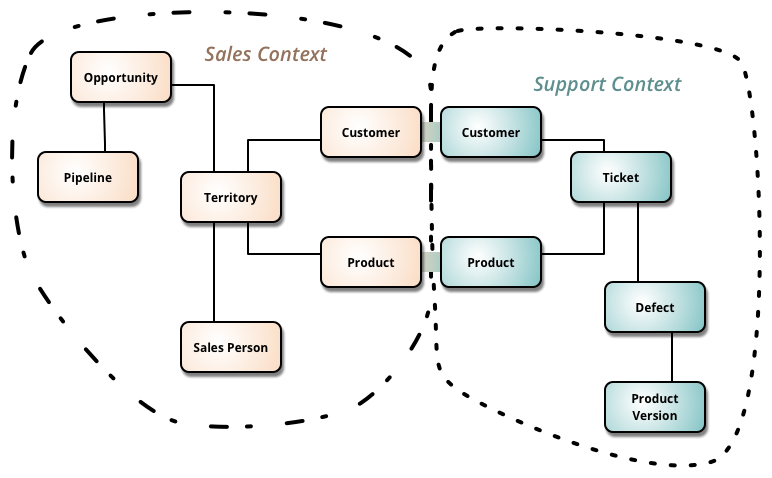
A bounded context is a context where a concept has a specific model. Generally, we may have multiple models for the same concept but not within the same bounded context.
Having a ubiquitous language does not mean we only have one model for a concept everywhere. If you take notice that 2 models have appeared for the same concept, then maybe there are 2 problems on the table to be solved. Two bounded contexts are probably there. Probably. It is an indication. Not a rule.
DDD tries to help you discover parts of your domain that could probably work autonomously. In order to achieve that, what you mainly need to analyze is your business domain. Not your code domain. Some of the clues DDD is using in this process of discovering bounded contexts are:
- linguistic boundaries: when the discussion on a part of your domain uses a very different vocabulary/terminology from the one used on another part, then this is a sign that these two parts show a level of independence between each other.
- existing organization boundaries: e.g your company has discrete departments handling these business subdomains.
- domain expert boundaries: e.g your company is using different experts or teams of experts for each part of the domain you examine.
- business process steps: you observe that there are some processes in your business that are executed in steps (pipelines). These steps may consist independent parts of your business domain. Independent not in the spirit of not using each other but in the sense that each one does not care how the other works internally but only what kind of services it provides and how these can be used.
- data: different domain experts talking about same entities but want to store totally different things about them (or some may need to store 100 properties of an entity and the other need to store just 10 properties of this entity)
Importance: Why bounded contexts are important ? Because they can help you identify parts of your system that are less coupled to the rest of it (here, we are talking about coupling at the level of business logic, behavioral coupling) and so they are better candidates for technical decoupling (separate those parts into distinct components or services).
The goal here is not to reduce the overall complexity of our system but to become able to deal with it. Splitting a component with a complexity of 6 into two components of complexity of 3 doesn’t reduce the overall complexity but it reduces the cost of extending or maintaining our system. Working with smaller components is easier and faster and we can allocate our resources (developers, testers, deployment pipelines, etc.) more efficiently.
Technical decoupling is important for systems that grow large. If the company business grow enough, every monolith will come to a point that needs, at first, better internal structure (modularization) and, later, extraction of some parts to external (micro)services. Long gone are the days where we were trying to come up with a number of code lines that will justify or put a size limit to a microservice (e.g 400 lines or 1000 lines or Fred George’s statement that “One page of code is a good size for a microservice”). Any of these number seems to be irrelevant because they can tell you absolutely nothing about the inter-dependencies between the microservices that will be created and the problems that will rise because of these inter-dependencies. [3]
Usually bounded contexts tend to be small. It is not easy to find extensive parts of your business that will keep the meaning of a concept/model strict and consistent. [3] Except if your business domain is really small. 🙂 Many people make the mistake to identify the size of a bounded context to the size of an independent service. Think of the monolith. All the business domain, and so all bounded contexts of this business domain live inside this monolth. And after some time, we are forced to start extracting parts of this monolith to additional services. Since this extraction is not easy, we tend to extract small pieces. So, we create small/micro-services. Though a microservice can rarely be bigger than a bounded context (there is rarely a good argument to do such a thing), it may end up being smaller than a bounded context. [4]
Side note 1: Beware of domain experts
There are a couple of things that we need to keep an eye for in our contact with the domain experts. They can explain us how the business work and what they want to achieve but, sometimes, they also tend to impose a solution to us. How this can be achieved. How the software should be designed. There are some fundamental problems with this. First, in big systems, usually each expert is an expert to a part of the domain. The business sector that the expert works and expertises in. [8] And, sometimes, even though all these sectors have to cooperate, they are not doing it willingly or they may be competitive, if not even hostile, to each other. [9] No matter if you are building a software solution that is supposed to serve all of them. Each one may direct you to a solution that serves best its own interest. Second, they don’t have the technical background to understand the implications of a design decision. Leave alone to choose between alternatives that may exist in domain modeling and software design.

Third, most of us that have dealt in the past with requirement analysis know what a challenge is to distinguish between what the client thinks that he needs and what he really needs.
The earlier we make this clear, the less times requirements will change by the client during the development. Yes, the movement of agile software development has made some steps there in integrating changing requirements but we don’t need to make our life harder without reason.
Gathering information from domain experts of all business areas/sectors helps us identify which problems/areas need more attention. Usually, the time and the budget we have available to develop a software is limited and because of that an ideal solution can not be delivered. Every expert will present as most important the needs of its own department/domain. We need to identify the main bottlenecks of the company that our system should focus on. DDD has done some good work here providing techniques and methodologies on how to deal with information gathering from domain experts (e.g the need to improvise, bringing experts from different domains together, avoid confusing examples with rules, etc.).
Let’s also keep in our minds that, when the software is supposed to implement an existing real-world process, this information gathering mostly happens at the initial part of the development and its goal is not to model the software but the process. How business work in real life. Alberto Brandolini is one of the popular names in this area because he emphasizes on the requirement analysis and the high level design of software functionality (not architecture). In that basis, he points out the importance of understanding the business domain in those phases.
Side note 2: The tactical pattern of Domain Events
One more tactical pattern. Nothing more, nothing less. But one that was not included in the original Eric Evans’ book but added as an appendix later because its importance came up on the way [11]. It makes sense, though. The idea of decoupling a monolith through modularization and, even more, the SOA variant of microservices, the popularization of asynchronous communication (all about decoupling, again) between them and the concept of eventual consistency, all emerged after 2003.

A domain event is an occurrence of something interesting that happened in the domain. Let’s elaborate a little bit on this. First of all, it represents something that has already taken place.
It is like a “news” item, a notification. Information about a change that has happened. Not a “call to arms”, a request for an action. Second, this occurrence happened in the domain. Not outside of it. So, an HTTP request knocking the door of our application is not a domain event, per se. In order to have a domain event, a change in our domain state has to take place. A user registration may be a domain event. The cancellation of an order. The payment of a pending invoice.
Third, it has to be something interesting. Not any change that happens in the system state. But interesting for whom ? For the domain experts. For company’s business. So, it is not a technical thing (an arrival of a web request, an item added to a queue, a script that was executed by cron , etc.). Let’s take the user registration example and let’s assume the registration happens in 5 stages. No user is added to the system until all stages are completed. Do we need an event for the completion of each step. For example, if the completion of the first step is something not important itself to the business expert, then no. Maybe, for the company’s business, not even the completion of the registration is an important event that domain experts need to know. Maybe, there is no business-related action that needs to be taken when a registration completes.
Domain events are designated to be used as a building block for a resilient system. Splitting a large business transaction into smaller ones where each one, beside the first, is triggered by the completion of the previous one. This completion is signaled by the publishing of an event. So, domain events are not meant to be used for synchronous communication. We store them and then we notify (actively/push or passively/pull, it doesn’t matter) any party concerned, module or service (process). How fast a domain event will or should be processed (temporal decoupling) by a concerned party is totally up to it. If we will, we could create more than one events for the same change in order to serve the needs of different bounded contexts (different information may be needed by each one in order to be properly notified about the system change that happened).
Domain events do not bring only resilience but they reduce the impact of locks to the database (a bigger transaction is split into smaller ones or maybe the database itself is split and the smaller transactions happen in completely different databases).
The concept of a domain event is not a technical thing. Domain events actually express a part of a business process that says “when this happens then that action should be taken”. If, for example, “this” happens in sales department and “that” is an action that should be taken by the warehouse, then we need a way for sales to notify the warehouse. So, we need to model a kind of message that will contain information from sales, about “this” event, that is needed by the warehouse in order to take “that” action.
From another viewpoint, a domain event is a concrete and independent representation of a state change that will be stored separately as a stand-alone entity. This was not the case when we were regularly reading the system state itself (no matter how, it could be synchronously by using database triggers or asynchronously by making regular queries to the database or checking the contents of a directory) in order to detect changes to it and trigger an action.
Side note 3: The tactical pattern of aggregates
What is an aggregate ? It is “a cluster of domain objects that can be treated as a single unit” [6]. Or, more theoretically, “something you think as a conceptual whole which is also made up of smaller parts” [10]. It says nothing about the kind of business objects or the number of them included in an aggregate or if there should be a “root” object. Yes, not even the existence of a root object is a requirement. [10] What is important is that this cluster of objects represents a real world concept of your domain and that there are (business) rules governing this cluster. So, consistency needs to be maintained when making changes and state management of an aggregate should be kept within a single transactional boundary. [7] You cannot start a transaction, make some changes to the aggregate that put it in an invalid state, commit them and then start another transaction to make the rest of changes to the cluster. We also need to keep in mind that aggregates are not a thing for the domain experts. It is a technical solution. A design pattern. A discussion about aggregates is one that takes place only among software developers. [8] It’s an implementation detail that, of course, helps us to maintain the domain invariants of the concept it represents. A rule of thumb on whether some concepts should form an aggregate is whether they are created, live and die together. Usually, if you decide to make an entity a property of another entity, then they should probably form (as a whole) an aggregate.
A typical example of an aggregate is an “order” object that contains a list of “order item”. Adding or removing order items to the order or calculating the total cost of an order can happen only through the order object. No direct access to the list or order items should be provided outside the boundaries of this order object. This makes it easier to maintain the domain/business invariants (e.g an order can have up to 5 order items, the total cost of an order cannot be higher than 5K).
[1] “Is Domain-Driven Design overrated ?” , Stefan Tilkov , GOTO 2021 , https://www.youtube.com/watch?v=ZZp9RQEGeqQ
[2] “Stop dogmatic Domain Driven Design” , Derek Comartin, June 2021 , https://www.youtube.com/watch?v=8XmXhXH_q90
[3] “Microservices and Domain Driven Design”, Vaughn Vernon, 2017, https://www.youtube.com/watch?v=3o4_FWk6JOQ
[4] “Monolith to Microservices”, Sam Newman, 2019, O’ Reilly
[5] “What is DDD” , Eric Evans, DDD Europe, 2019 , https://www.youtube.com/watch?v=pMuiVlnGqjk
[6]. “DDD_Aggregate”, Martin Fowler, https://martinfowler.com/bliki/DDD_Aggregate.html
[7]. “Sam Newman on Information Hiding, Ubiquitous Language, UI Decomposition and Building Microservices”, InfoQ, https://www.infoq.com/podcasts/sam-newman-ddd-microservices/
[8]. “Event Storming”, Alberto Brandolini, DDD Europe 2019, https://www.youtube.com/watch?v=mLXQIYEwK24
[9]. “Domain Driven Design: The good parts”, Jimmy Bogard, NDC {Sydney} 2016, https://www.youtube.com/watch?v=U6CeaA-Phqo
[10]. “What I have learned about DDD since the book”, Eric Evans, QCon London 2009, https://www.youtube.com/watch?v=lE6Hxz4yomA
[11]. “Event-Driven SOA: Events Meet Services”, Oracle Technical Article, 2011, https://www.oracle.com/technical-resources/articles/middleware/soa-schmutz-soa-eda.html